
These are programmers' development tools, rather than end-user tools. DCOM is Microsoft's attempt at CORBA implementation, SOM and DSOM are IBM's offering and Sun Microsystems provides RMI. These are all attempts to make it easy for programmers to write software that shares its data objects with other programs. They do not have a very large or direct impact on our data discovery and retrieval problem.
This is a promising approach, based on open non-proprietary standards, which are free (no licensing or royalty issues). Although SGML is mature and has an established user base, XML is a new application of SGML and is not well-developed yet. There are XML projects being developed that look very promising in regard to our problem. Like other SGML applications, XML is extensible and human-readable (rather than binary data; this allows skilled users to easily correct problems using nothing more than a simple text editor).
SQL is good at manipulating database elements, but poor at data discovery tasks. We (in this class) have learned to use Oracle's data dictionary to list table names and its DESCRIBE command to retrieve a description of data elements defined for each table, but these are specific to Oracle. Other database systems offer similar mechanisms, but the SQL standard does not include any of them. You must know something about the target database in order to retrieve any information from it, and SQL has no method of discovering the features of the target system.
These are essentially ways to extend SQL, and they share SQL's limitations, as well as being primarily development tools. Each database software system provides an ODBC/JDBC interface, which translates incoming ODBC requests and provides the requested data. These are proprietary solutions from Microsoft and Sun, and are not based upon official industry standards.
This is an open, non-proprietary standard, which is good for data discovery and simple queries but doesn't permit table joins, indexing, or calculations. It includes an extension mechanism to provide additional functionality for specific user communities, but relies upon predefined schemata (doesn't facilitate ad-hoc queries). Since it was this protocol that sparked my interest in this topic, and it was less familiar to me (and probably to other class members) I will spend a bit more time on it.
Z39.50 is like SQL in that it can be used from a simple text-based interface like telnet. Also like SQL is its standardized set of commands or operations. And, just as with SQL, there are client software programs designed to hide the text-based interface and provide the user with a friendlier menu-driven or window-based interface.
Here are displays from one freely available Z39.50 client:
Some of the available database providers.
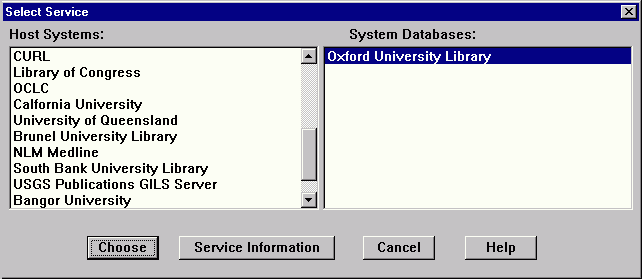
A query of the MedLine database. Notice there are only five data fields available to query from. This query resulted in 1,361 hits. The client software retrieved the first ten automatically; the "More Titles" button retrieves additional record descriptions.
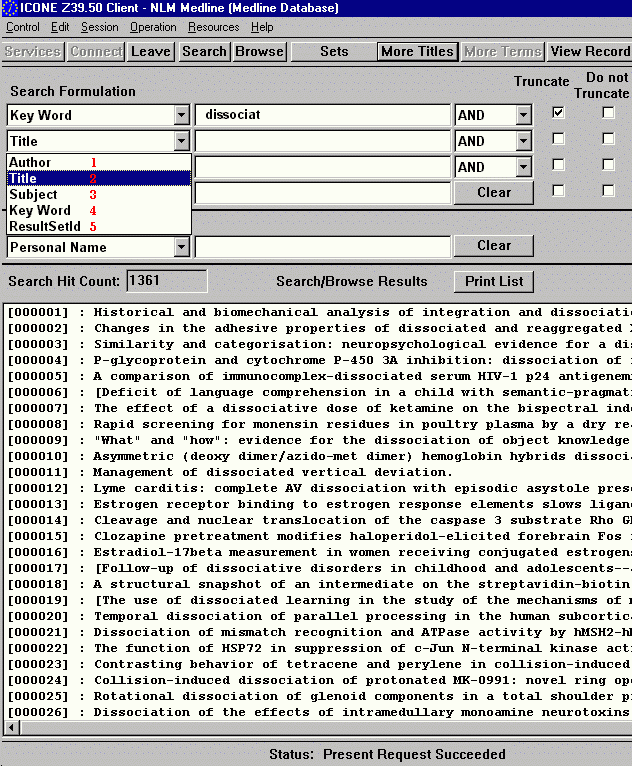
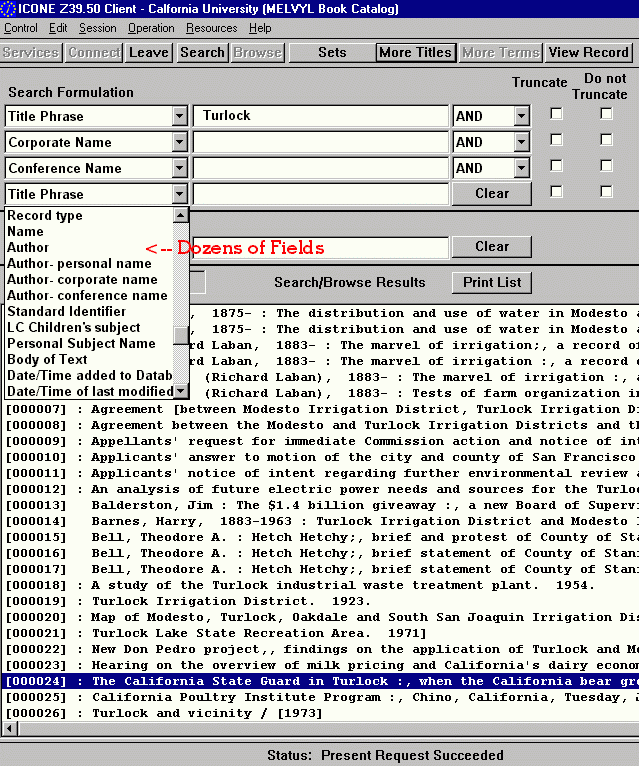
University of California's MELVYL book catalog offers dozens of searchable fields. This query returned 172 hits.
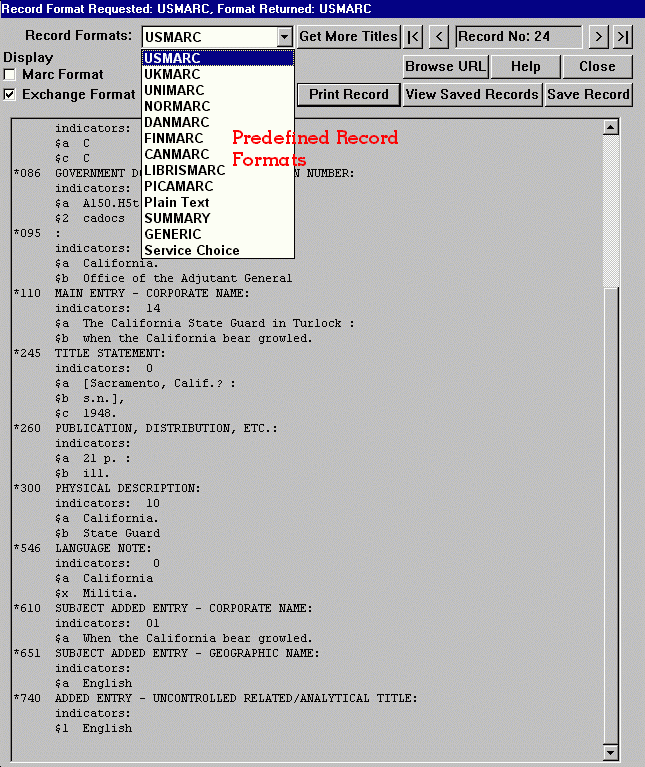
A complete record returned by MELVYL. This record is in the USMARC format, which is designed to be easily imported into other bibliographic software. The client and the server have negotiated a common record format based upon the user's request.
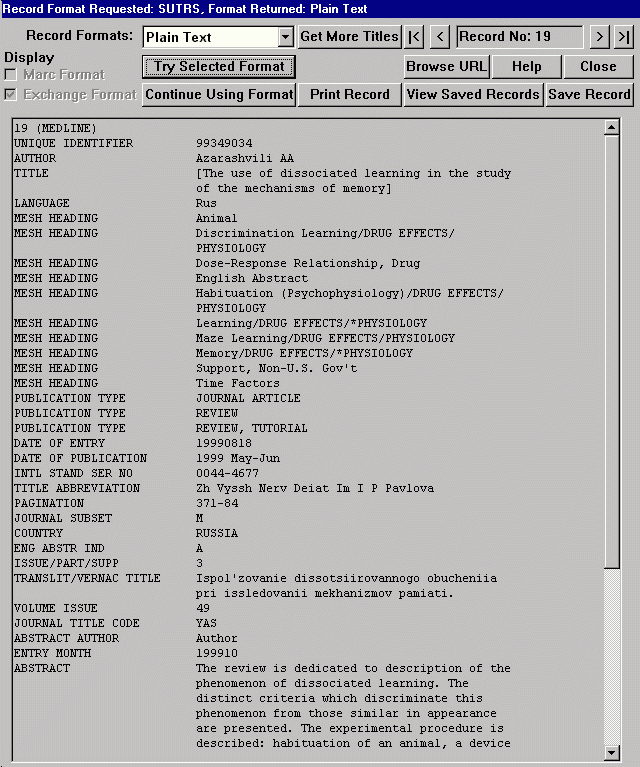
Here, the MedLine server originally returned a record in SUTRS format, but the user then requested a plain text version.
One of the most crucial features of Z39.50 is its EXPLAIN command. This allows the client to request information from the server about what data is available, including the record structures of its exposed datasets. Once the user sees what data fields are available, it is possible to structure a meaningful query.
This extension of the Z39.50 standard will combine the best features of Z39.50 and SQL. It will offer the data discovery features of Z39.50's "EXPLAIN" command, and the ability to conduct complex queries, calculation, and data manipulation provided by SQL. All of this can be available to sophisticated users with a command line interface (no expensive, proprietary SDK), or hidden behind a GUI client program. Here is how the Distributed Systems Technology Centre (a consortium sponsored by the Australian government) describes it:
Z+SQL can be seen as an extension of the existing Z39.50-1995 (Version3) protocol, uniting the advantages of SQL's query language and export syntax with the information retrieval services of Z39.50. The SQL extension provides a standardized way of specifying complex structured queries which otherwise are difficult/not possible with the existing Z39.50 query types. In addition, result sets (which may contain complex data types) may be returned in a generic record syntax without having to tag each individual field of each record and without being tied to a pre-defined schema. The Z+SQL standard remains platform and database independent. Indeed, the supporting database may be an RDBMS, OODBMS, O-RDBMS or even a text database for that matter. As is now the case with Z39.50, the onus is on the server to map the Z39.50 PDU's to the applicable database calls.
Z+SQL provides the Z39.50 client with the full flexibility and query power of SQL. Z+SQL clients are able to specify complex queries, either by using SQL or one of its derivatives, such as Query-by-Example (QBE). Queries can be formulated on single (virtual) tables, as in now the case, or multiple tables supporting cartesian products, unions, intersections, joins on matching columns, and projections on given columns. Queries can also be formulated using powerful constructs for expressing conditions, performing aggregate and comparison operations, partitioning tables into groups and much more. (more)